Dealing with Ambiguous or Vague Information

Question: Which type of AI System assigns values of 0 and 1 to vague or ambiguous information?
Artificial intelligence is capable of processing massive amounts of data. Some of the best models that we have seen have more parameters in them than we can even imagine. Take the new GPT-2 model from OpenAI for example, where there are over 1,500,000,000 parameters that the model has learned. With computing power that keeps growing, this can expand rapidly too. In every dataset, however, there are features that are deemed to be the most important. In other words, not all of the information that is fed into a model is useful. In some cases, it can even lead the model astray and affect model performance by allowing it to learn a dependency that is not there. In other cases, data may be missing due to the answer not being applicable to a candidate being asked a question by a researcher, for example.
How can we deal with information that is vague or ambiguous? Is it worth even including this information in the model? In this post, I will walk through these scenarios and explain the answers.
Dealing with information that is ambiguous or vague
Buckets of information can be thought of as feature engineering. The feature is being altered from what it originally was into something new. As one of these buckets, the person in example #1 could be uncertain of their answer. Not being sure is a perfectly fine answer. This can be recorded as such.
Fuzzy logic
In practice, few things in machine learning are black and white. As data scientists work to unravel the meaning in data, they must understand to some extent what it means and the range of possibilities that one of their features includes. They must determine under what circumstances the data was collected, too.
Technically, fuzzy logic is a type of logic that is not binary logic meaning things can be just 0’s or 1’s. Rather it allows values to be any value between 0 and 1 (inclusive).
An example that we can consider when talking about fuzzy logic is the temperature that we like our homes to be at. We don’t think in black and white in this regard either. We don’t feel only hot or cold, there is a range of temperatures that make us feel comfortable or not comfortable. In this case, fuzzy logic can be used to deal with this range of outcomes. In the graph below, fuzzy logic is used to create buckets for each of these conditions:
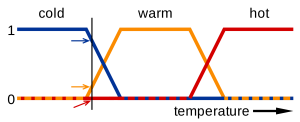
Creating buckets is a useful way to add human insight to a feature in your dataset, too. Instead of allowing the model to find relationships for each discrete value of temperature and how it relates to an output parameter, you are bucketing it into just 3 values (cold, warm, hot) so that it doesn’t need to figure out the relationship itself. Any bit of human intuition that we can provide a model will help it learn.
Dealing with missing values in machine learning
Example 1. For this article, I would like to propose that we think about several examples. Typically, we look at data day in and day out whether at work or school since you love data (likely why you’re reading this article). It is easy to forget occasionally that the data that you see in spreadsheets or in your python plot was collected by someone or something.
Imagine you are a researcher who is asking people who signed up to take part in a scientific study a series of questions. Think about the types of answers that people really give when asked questions. For example, the interviewer could ask what is the quality of your sleep? To that, they would receive a mixed bag of results such as Excellent, terrible, alright, OK. Bucketing these responses into something more useful is needed. Another response that would be received would be not sure indicating the person has uncertainty about how well they really sleep. It’s not a missing value, but it’s not a firm answer either.
In example 1 above, scenarios where a question didn’t apply to a patient, received a score of N/A. Just because some of the patients receive a N/A for that question, does that mean we should completely remove that record from our model? The answer is tricky, but typically we want to find ways to include that record since we want as much data as possible.
There are several great ways to deal with missing values besides removing the record. They typically involve filling the missing data with a value that won’t disrupt the prediction. Some of the common approaches to filling in missing data points are:
- Use the Median of the column
- Most common value
- Impute with a machine learning technique such as K-Nearest Neighbors
For more details on how you can fill in missing values, please visit this blog article.
Concluding Remarks
Data in machine learning is rarely cut and dry. At least for now, the human element of machine learning is very important. We need to help out the model as much as possible. As such, digging a little deeper into ways this can be done such as finding ways to handle missing values helps.
Artificial intelligence is capable of incorporating soft data into models, but we need to help it along.
Read More From AI Buzz

AI Art Revolution: Create Stunning Masterpieces Without Being an Artist
Want to create stunning, original art in seconds, even if you’ve never picked up a paintbrush? AI art generators are making it possible. With just a few words or an image, you can now generate unique artwork, opening up a whole new world of creative possibilities. This article will show you how. However, it is […]

Install TensorFlow on M1/M2 Macs (2024): Step-by-Step Guide & Troubleshooting
🚀 Quick Overview Last Updated: December 2024 Tested On: M1 and M2 Macs (macOS Sonoma) Reading Time: 10 minutes Difficulty: Intermediate Installing TensorFlow on your M1 or M2 Mac can be tricky, but it doesn’t have to be. This step-by-step guide, last updated in December 2024 and tested on macOS Sonoma, will walk you through […]