
Actor-Critic Model Prevents Compounding AI Hallucination

A recent technical analysis has brought a critical architectural solution to the forefront of the AI development community, directly addressing the systemic risk of agent hallucination. The pattern, known as the Actor-Critic model, is gaining traction as a foundational blueprint for building reliable multi-agent systems. This design moves beyond simply scaling models and instead introduces a verification layer to prevent the compounding errors that have plagued early autonomous agent implementations.
This architectural shift is not merely theoretical; it reflects a broader industry move toward verifiable agentic orchestration. The principles behind the Actor-Critic model are now being validated by the rapid commercial success of companies employing similar multi-agent strategies and by academic research quantifying their superior performance. This development signals a significant maturation in the approach to building dependable, production-ready AI.
Key Points
- Using the Actor-Critic model to prevent AI agent hallucination works by separating generation (Actor) and validation (Critic) tasks into distinct roles.
- Commercial validation for this approach is demonstrated by Manus AI, whose multi-agent architecture helped it reach $100 million ARR in eight months.
- Research from Anthropic shows orchestrated multi-agent systems outperform single agents by over 90% on complex benchmarks.
- This architecture enables advanced AI agent governance and cost reduction by using different models for generation and validation.
When Agents Echo Their Own Lies
In complex AI systems, the unmoderated interaction between agents can create what one analysis calls a “toxic relationship.” According to the article “Toxic Relationships 💔: When Your Agents Hallucinate,” when a primary agent hallucinates and a worker agent accepts that output as fact, the system’s shared understanding, or “global state,” becomes corrupted. Every subsequent action is then “built on a lie,” amplifying the initial error in a dangerous feedback loop.
This problem represents a fundamental “usability ceiling” in generative AI. Academic research formalizes this as the “Intent-Execution Gap”—the disparity between a user’s goal and the unpredictable output of generative models. A paper on the Vibe AIGC framework notes that this gap makes the creative process a “fragile exercise in stochastic trial-and-error.” The agentic echo chamber is a direct result of this gap, where the system fails to reliably execute the user’s true intent.
Checks and Balances for Thinking Machines
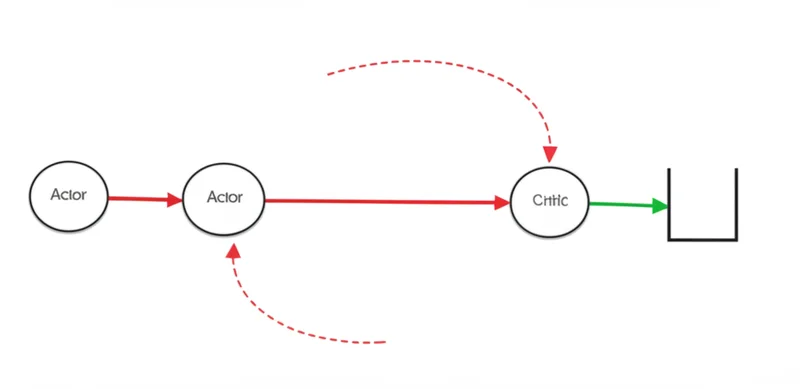
To dismantle this echo chamber, developers are implementing the Actor-Critic architecture for LLM agents. This pattern establishes clear boundaries by separating the process of generation from validation, creating a system of checks and balances. The workflow involves three distinct roles: a Lead Orchestrator to deconstruct the user request, an Actor agent for generation, and a Critic agent for validation.
The Actor proposes a solution, such as a piece of code or a plan of action. Before this proposal can be executed, it is sent to the Critic. The Critic’s sole function is to verify the Actor’s output against a set of rigid constraints, schemas, or an independent source of truth like a read-only database. This external truth source is critical, as the Actor cannot alter it, effectively breaking the feedback loop that causes hallucinations to compound.
If the Critic rejects the proposal, it is sent back to the Actor for revision. If approved, it can proceed to a human-in-the-loop gate or directly to execution. This iterative process, as noted in a summary of recent research, pairs an “Actor agent with a Critic agent” to systematically improve reliability.
Breaking the Monolith: The Rise of Micro-Agents
The Actor-Critic model is a key component in one of the latest trends in reliable autonomous AI agents: the industry-wide shift from a “Model-Centric” approach to what some researchers call “Agentic Orchestration.” Instead of relying on a single, massive model, value is now derived from the structured collaboration of multiple specialized agents. This is one of the AI orchestration patterns for production that is showing substantial results.
The commercial success of Manus AI provides powerful evidence for this trend; a recent report highlights that the company reached $100 million ARR in just eight months by using an architecture of planning, execution, and validation agents—a direct commercial parallel to the Lead Orchestrator, Actor, and Critic roles. Further validating this, research from Anthropic cited in the same report found that multi-agent systems with Claude Opus 4 outperformed single agents by 90.2% on research benchmarks. Advanced frameworks, detailed in publications like the Lemon Agent Technical Report and the paper on FlowSearch, also build on these core principles of task decomposition and verification.
The Economics of Trustworthy AI
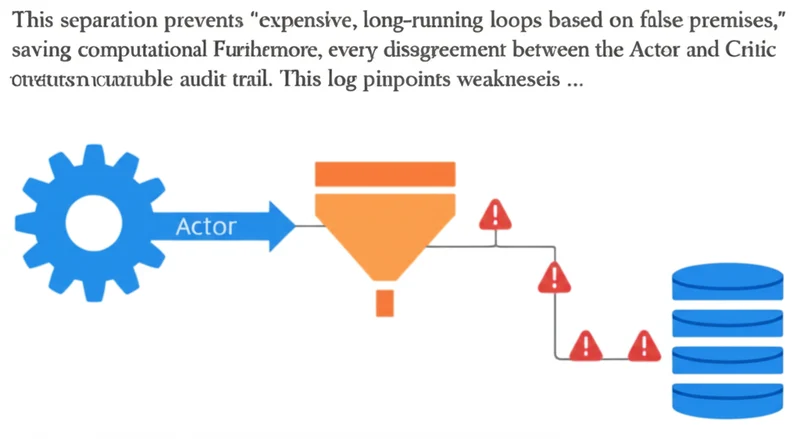
Adopting an Actor-Critic architecture delivers significant operational benefits, transforming AI initiatives from high-risk experiments into governable systems. The primary advantage is a dramatic reduction in erratic behavior, as the Critic acts as a quality control gate. As one technical breakdown explains, this design enables novel strategies for AI agent governance and cost reduction. For example, a faster, cheaper model can be used for the Actor’s creative generation, while a more powerful, expensive model is reserved for the Critic’s high-stakes validation task.
This separation prevents “expensive, long-running loops based on false premises,” saving computational resources. Furthermore, every disagreement logged between the Actor and Critic creates an invaluable audit trail. This log pinpoints weaknesses in prompts or models, providing a clear roadmap for system refinement and making the entire process more efficient and auditable.
Engineering Trust Into AI’s DNA
The challenge of agent hallucination is proving to be solvable not merely by scaling models, but through superior architectural design. The Actor-Critic pattern provides a practical and powerful framework for building autonomous systems that are verifiable and robust by embedding validation directly into the workflow. The commercial and academic momentum behind multi-agent orchestration confirms that this is the direction for building complex, reliable AI.
By designing systems that rigorously challenge their own assumptions, developers are moving beyond blind trust to create auditable and scalable AI partners. As these orchestrated systems become more integral to enterprise operations, how will automated verification evolve to manage even greater complexity and ensure mission-critical reliability?
Read More From AI Buzz

Perplexity pplx-embed: SOTA Open-Source Models for RAG
Perplexity AI has released pplx-embed, a new suite of state-of-the-art multilingual embedding models, making a significant contribution to the open-source community and revealing a key aspect of its corporate strategy. This Perplexity pplx-embed open source release, built on the Qwen3 architecture and distributed under a permissive MIT License, provides developers with a powerful new tool […]

New AI Agent Benchmark: LangGraph vs CrewAI for Production
A comprehensive new benchmark analysis of leading AI agent frameworks has crystallized a fundamental challenge for developers: choosing between the rapid development speed ideal for prototyping and the high-consistency output required for production. The data-driven study by Lukasz Grochal evaluates prominent tools like LangGraph, CrewAI, and Microsoft’s new Agent Framework, revealing stark tradeoffs in performance, […]

UChicago AI Model Beats Optimization Bias with Randomness
In a direct challenge to the prevailing “AI as oracle” paradigm, where systems risk amplifying existing biases, researchers at the University of Chicago have demonstrated that intentionally incorporating randomness into scientific AI systems leads to more robust and accurate discoveries. A study published in the Proceedings of the National Academy of Sciences details a computational […]