
AI Agent Architecture Solves 95% Enterprise ROI Failure

A staggering 95% of organizations are realizing zero return on their generative AI investments, a figure highlighted in an announcement citing an MIT study, pointing to a widespread disconnect between technological hype and business reality. This 95 percent enterprise AI failure rate is now being linked to a critical but often-overlooked factor: architectural mismatch. A recent analysis highlights how the fundamental design of an AI agent—how it “thinks”—directly dictates its cost, speed, and effectiveness, revealing that using the wrong tool for the job is a primary driver of failed AI initiatives.
The core issue, as detailed in an analysis from Towards AI, is the failure to distinguish between different agent architectures. By categorizing agents into Shallow Processing, ReAct, and Deep Reasoning patterns, the analysis provides a framework for understanding why a one-size-fits-all approach leads to significant enterprise AI cost overruns and poor performance. This distinction is not merely academic; it is central to solving the current AI agent architectural mismatch ROI crisis plaguing the industry.
Key Points
- An MIT study finds 95% of organizations see zero return from GenAI, highlighting a widespread strategic failure.
- AI agent architectures are categorized as Shallow, ReAct, and Deep Reasoning, each with distinct cost and latency profiles.
- Architectural mismatch—using the wrong agent for a task—is identified as a primary cause of ineffective AI and high costs.
- A tiered system that routes requests by complexity is a practical solution to optimize both performance and budget.
The Thinking Spectrum: Fast vs. Deep
The choice of an AI agent’s architecture determines its fundamental capabilities. The analysis breaks these down into three primary patterns, each suited for different types of problems.
Shallow Processing is the efficiency engine, executing tasks in a single pass from input to output. Ideal for high-volume, low-complexity work like summarizing notes or classifying tickets, this pattern is estimated to be suitable for 70% of use cases. Its weakness is an inability to handle complexity or use external tools, making it prone to confident hallucinations.
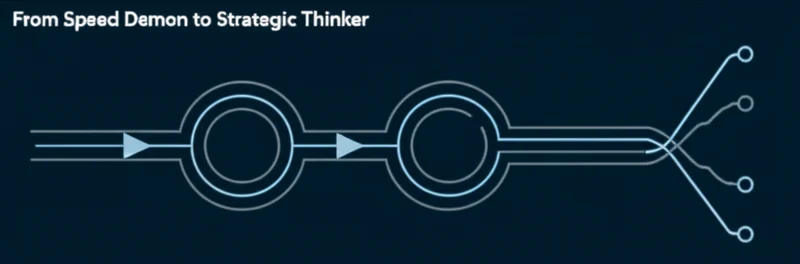
The ReAct (Reasoning + Acting) pattern is the pragmatic workhorse, operating in an iterative loop to use tools and interact with external data. This architecture is the sweet spot for many production systems, such as a customer service agent that needs to call multiple APIs to resolve an issue. While each tool call adds a delay, a key consideration in the latest on AI agent latency and cost, this approach is essential for dynamic, real-world problems.
Deep Reasoning represents the strategic thinker, designed for intensive, offline computation. These agents explore multiple solutions and edge cases in a hidden internal monologue, often taking 30-60 seconds or more to produce a refined answer. This architecture is necessary for tackling genuinely complex problems that standard LLMs cannot handle, a gap highlighted by new expert-level benchmarks like Humanity’s Last Exam (HLE) which show a marked gap between current LLM capabilities and the expert human frontier.
The 95% ROI Crisis Explained
The 95 percent enterprise AI failure rate cited in a PR Newswire release on the AI company Poetiq is a direct consequence of ignoring these architectural distinctions. The problem is architectural mismatch: applying the wrong type of “thinking” to a task. Using an expensive deep reasoning model for simple classification leads to prohibitive costs, while deploying a shallow model for complex research results in an ineffective, error-prone system.
This mismatch is the root of widespread enterprise AI cost overruns, and misusing deep reasoning for simple tasks is a primary cause. As Shumeet Baluja, a former Google DeepMind researcher, notes, “LLMs are impressive databases… They are simply not the best tools for deep reasoning.” This perspective underscores that architectures like deep reasoning are not just features but fundamentally different capabilities. The failure to make this distinction is a primary reason why massive investments are failing to deliver value.

Orchestrating Intelligence: The Tiered Approach
The most effective strategy to emerge from this analysis is a tiered approach that intelligently routes requests based on complexity. This model optimizes for both performance and cost by matching the task to the right architecture. A typical system might route 80% of simple requests to a fast, cheap Shallow agent, with more complex queries escalated to a ReAct agent. Only a small fraction, perhaps 1-5%, of truly difficult problems would be reserved for a Deep Reasoning agent.
This tiered strategy aligns with broader industry trends moving away from monolithic models. Companies like Poetiq are developing “AI meta-systems” that generate specialized agents, while academic research into multi-agent frameworks like MCP-SIM demonstrates how “iterative plan–act–reflect–revise cycles” can improve robustness. This evolution in the discussion of Shallow vs ReAct AI for production signals a shift toward more sophisticated, specialized, and collaborative agent frameworks.
Right Tools, Right Tasks: The Architecture Imperative
The distinction between Shallow, ReAct, and Deep Reasoning provides a critical framework for building AI systems that deliver tangible value. The analysis presented in Choosing AI Agent Architecture for Enterprise Systems: Shallow vs ReAct vs Deep | Towards AI is validated by market data and expert commentary, confirming that architectural choice is a determining factor in success.
For developers and business leaders, the path forward involves moving beyond the hype of a single “most powerful model.” By consciously selecting the appropriate architectural pattern for each task, organizations can build solutions that are not only capable but also practical and cost-effective. As agent frameworks become more advanced, will organizations develop the strategic discipline to choose the right tool for the job, or will they continue to chase the most powerful one?
Read More From AI Buzz

Kimi K2.5 Agent Swarm Challenges Alibaba in Enterprise AI
Moonshot AI has released Kimi K2.5, a new open-weight model that signals a significant strategic pivot from conversational chatbots toward autonomous systems. The release integrates advanced vision capabilities with a sophisticated multi-agent architecture termed “Agent Swarms,” directly challenging competitors like Alibaba for dominance in the enterprise automation market. This move underscores a broader industry trend […]

Kyutai's Hibiki-Zero: RL-Powered S2ST Without Alignment
Kyutai, a European open science AI research lab, has introduced Hibiki-Zero, a 3-billion-parameter model that marks a significant advancement in simultaneous speech-to-speech translation (S2ST). The primary innovation of the Kyutai new speech translation model is its ability to be trained without word-level aligned data, a traditional and costly bottleneck in S2ST system development, according to […]

Anthropic's $350B Valuation Challenges OpenAI & Google
AI safety and research company Anthropic is nearing completion of a historic funding round securing over $20 billion, a move that solidifies its position as a primary challenger to OpenAI and Google. The deal, which involves a formidable coalition of sophisticated financial players including quantitative hedge fund D.E. Shaw and venture capital firm Founders Fund, […]