
Kyutai's Hibiki-Zero: RL-Powered S2ST Without Alignment

Kyutai, a European open science AI research lab, has introduced Hibiki-Zero, a 3-billion-parameter model that marks a significant advancement in simultaneous speech-to-speech translation (S2ST). The primary innovation of the Kyutai new speech translation model is its ability to be trained without word-level aligned data, a traditional and costly bottleneck in S2ST system development, according to the lab’s announcement. By employing a novel reinforcement learning technique, the model learns to dynamically balance translation quality and latency, achieving state-of-the-art performance. This development simplifies the data collection process and enhances the model’s ability to adapt to new languages with less data, representing a notable step toward democratizing high-quality, real-time translation technology.
Key Points
- Kyutai has released Hibiki-Zero, a 3B-parameter model for AI speech translation without aligned data.
- The system uses Group Relative Policy Optimization (GRPO), a reinforcement learning method, to manage latency and quality.
- Its unified decoder-only architecture processes source audio, target audio, and text streams simultaneously.
- The model and its training code are open-source, providing a new foundation for S2ST research.
Breaking the Alignment Barrier
The most significant technical advancement of Hibiki-Zero is its capacity for AI speech translation without aligned data, which bypasses the traditional need for meticulously aligned audio. Historically, creating S2ST datasets required a painstaking process of aligning each word in source audio with its corresponding translated word in the target audio. This process is expensive, time-consuming, and a major barrier to scaling translation systems to many languages.
Hibiki-Zero circumvents this entirely. It begins its training with only coarse, sentence-level alignments, such as knowing that one audio file of a sentence in English corresponds to another audio file of the same sentence in French. This approach dramatically expands the pool of usable training data, as vast quantities of bilingual audio, like dubbed films or parliamentary proceedings, exist in this sentence-aligned format, a point emphasized by the Kyutai research team in their findings. The model learns the fine-grained translation policy through its subsequent training phase, a design that addresses a long-standing industry challenge.
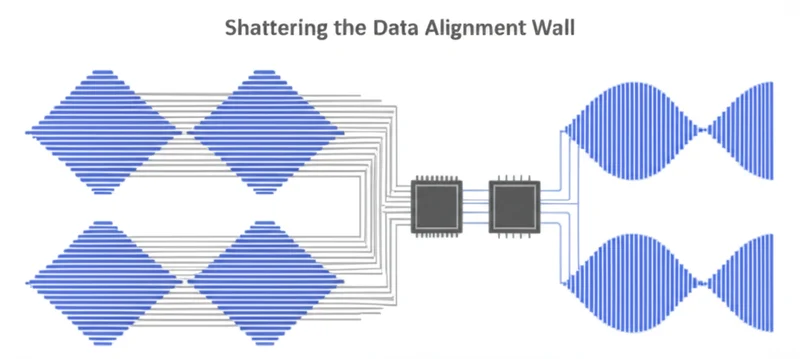
Decoding at 80ms: The Translation Architecture
Hibiki-Zero’s performance is rooted in a sophisticated architecture that rethinks fundamental aspects of speech models. At its core, it is a 3-billion-parameter, decoder-only model based on the RQ-Transformer architecture. Unlike traditional models that separate the tasks of understanding and generating, Hibiki-Zero uses a single transformer to process all data streams simultaneously, a design choice detailed in Kyutai’s technical overview.
Its “multistream” capability jointly processes source audio, generated target audio, and an intermediate “inner monologue” of text. This allows the system to learn the intricate relationships between source sounds, textual meaning, and target speech patterns within one cohesive framework. To enable real-time operation, the model uses the streaming Mimi audio codec, which converts audio into discrete tokens. It operates at a 12.5 Hz framerate, processing audio in 80-millisecond chunks, a rate suitable for conversational applications.
This simultaneous speech translation breakthrough is powered by a GRPO reinforcement learning model, which fine-tunes the policy for when to listen and when to speak, optimizing the balance between speed and accuracy without explicit alignment examples, a core achievement highlighted in the project’s documentation .
1,000 Hours: The New Data Efficiency
Kyutai’s research indicates that Hibiki-Zero not only introduces a more efficient training paradigm but also achieves top-tier performance. The model was benchmarked on five language tasks, demonstrating its robustness and high quality across accuracy, naturalness, and cross-lingual speaker similarity—the ability to preserve the original speaker’s vocal characteristics in the translated output.
A standout claim is the model’s data efficiency. Researchers demonstrated that Hibiki-Zero could be adapted to a new language, Italian, with less than 1,000 hours of audio data. This is a fraction of what is typically required to train a high-quality speech model from scratch. This “few-shot” adaptation capability is a direct benefit of the training methodology, which does not rely on scarce, perfectly aligned data.
It suggests the model learns a more generalized understanding of speech and language that can be quickly fine-tuned, significantly lowering the barrier to supporting less-resourced languages.
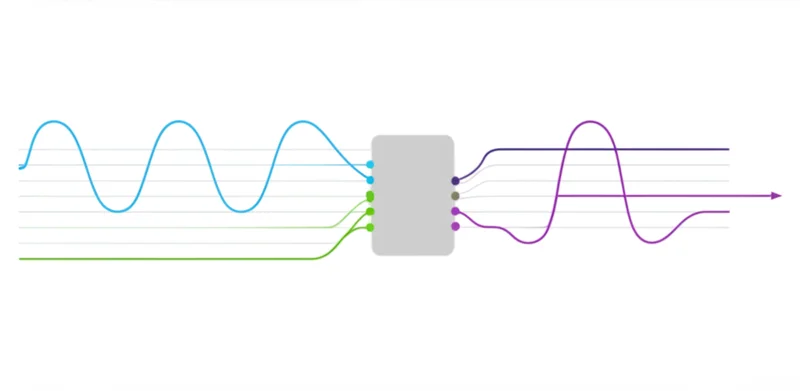
Open Weights, Open Innovation
The release of Hibiki-Zero is a notable development for the AI industry, particularly in real-time communication. By making the model, its weights, and the training code publicly available, Kyutai provides a powerful new tool for the global research community. This open-science approach directly challenges the strategies of major technology companies that have historically relied on massive, proprietary, and meticulously curated datasets.
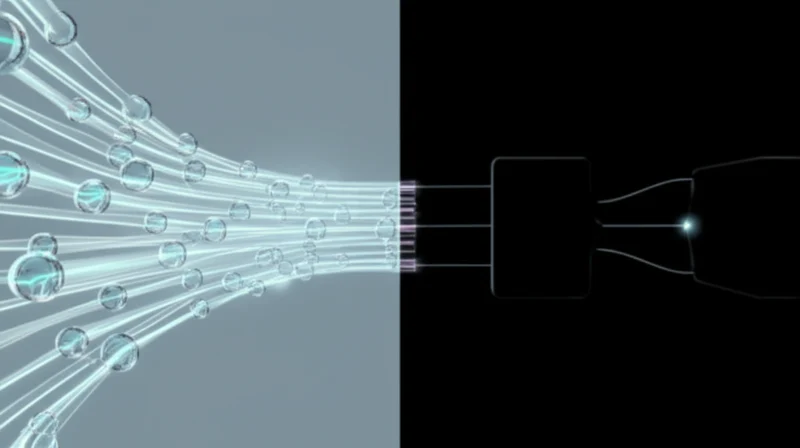
This Hibiki-Zero reinforcement learning speech translation sets a new benchmark. Its success with minimal data alignment may spur a shift in research focus across the industry toward more data-efficient methods. The open release invites researchers and developers to build upon this foundation on GitHub, accelerating progress in applications for international business, live events, and media. It provides a tangible asset for building the next generation of live communication tools.
From Bottlenecks to Breakthroughs
Kyutai’s Hibiki-Zero demonstrates a practical path toward high-performance, simultaneous speech translation that is less dependent on expensive, perfectly curated data. By combining a unified multistream architecture with a novel reinforcement learning strategy, the model achieves state-of-the-art results while establishing a new standard for data efficiency. The open-sourcing of this technology provides the community with a powerful new building block for cross-lingual communication. With the primary data bottleneck now addressed, how quickly will the industry adapt to this new paradigm for training translation models?
Read More From AI Buzz

Perplexity pplx-embed: SOTA Open-Source Models for RAG
Perplexity AI has released pplx-embed, a new suite of state-of-the-art multilingual embedding models, making a significant contribution to the open-source community and revealing a key aspect of its corporate strategy. This Perplexity pplx-embed open source release, built on the Qwen3 architecture and distributed under a permissive MIT License, provides developers with a powerful new tool […]

New AI Agent Benchmark: LangGraph vs CrewAI for Production
A comprehensive new benchmark analysis of leading AI agent frameworks has crystallized a fundamental challenge for developers: choosing between the rapid development speed ideal for prototyping and the high-consistency output required for production. The data-driven study by Lukasz Grochal evaluates prominent tools like LangGraph, CrewAI, and Microsoft’s new Agent Framework, revealing stark tradeoffs in performance, […]

UChicago AI Model Beats Optimization Bias with Randomness
In a direct challenge to the prevailing “AI as oracle” paradigm, where systems risk amplifying existing biases, researchers at the University of Chicago have demonstrated that intentionally incorporating randomness into scientific AI systems leads to more robust and accurate discoveries. A study published in the Proceedings of the National Academy of Sciences details a computational […]