
OpenAI Launches GPT-4.5 "Orion", A Stepping Stone in AI Scaling and Reasoning

OpenAI’s announcement of GPT-4.5, code-named “Orion,” marks a significant, albeit complex, milestone in the evolution of large language models (LLMs). While billed as OpenAI’s largest model to date, trained with unprecedented computational resources and data, its release has sparked a nuanced debate within the AI community.
This isn’t a simple story of bigger being better; instead, it’s a critical juncture that forces us to examine the limits of current AI scaling approaches, the rise of specialized reasoning models, and the ethical considerations surrounding increasingly powerful AI systems. This article will provide a comprehensive analysis of GPT-4.5 “Orion,” exploring its capabilities, limitations, and the broader implications for the future of artificial intelligence.

The Unveiling of GPT-4.5 “Orion”: A Giant Leap, a Costly Stepping Stone, or Both?
The arrival of GPT-4.5, long anticipated and code-named Orion, has been met with a mixture of excitement and cautious scrutiny. As reported by TechCrunch, OpenAI itself acknowledges that GPT-4.5 is not considered a “frontier model” despite its size, a notable statement given the ongoing debate about the potential risks of such powerful AI systems.
The model is currently available as a research preview, primarily to subscribers of OpenAI’s premium ChatGPT Pro service, priced at a hefty $200 per month. This immediately raises questions about accessibility and the potential for a widening gap between those who can afford the latest AI advancements and those who cannot.
Availability, Pricing, and Initial Reactions
The initial rollout strategy for GPT-4.5 underscores the immense resources required to develop and deploy such a massive model. While users of ChatGPT Plus and ChatGPT Team are expected to gain access “sometime next week,” the immediate focus on high-paying Pro subscribers highlights the economic realities of cutting-edge AI.
OpenAI states that GPT-4.5 was developed using the same key technique of unsupervised learning, dramatically increasing computing power and data. The industry has wondered if this approach will continue to show improvements. Indeed, OpenAI claims “deeper world knowledge” and “higher emotional intelligence.” However, there are already indications that the performance gains from simply scaling up are beginning to plateau.
The $200/month price tag for ChatGPT Pro access is a significant barrier to entry for many. While API access for developers on paid tiers is also available, the cost is steep: $75 per million input tokens and $150 per million output tokens. This GPT-4.5 API pricing is dramatically more expensive than GPT-4o, which costs just $2.50 per million input tokens and $10 per million output tokens.
OpenAI even admits that GPT-4.5 is “very expensive to run,” and they are evaluating whether to continue serving it in its API in the long term. This pricing disparity could limit the widespread adoption and experimentation that are crucial for understanding the full potential and limitations of such a powerful model.
The “Frontier Model” Debate and Ethical Implications
The release of GPT-4.5 reignites the crucial discussion surrounding “frontier AI models” – those with capabilities so advanced that they could pose significant risks to public safety. While OpenAI initially stated in a white paper that GPT-4.5 was not a frontier model, this line was subsequently removed.
The updated white paper omits this claim, leaving the question open. A TechCrunch article discussing the model’s codename notes the discrepancy, pointing out where the original document could be found. This ambiguity underscores the ongoing challenge of defining and regulating these powerful AI systems.
The very existence of models like GPT-4.5 raises profound ethical questions. Who controls access to this technology? How can we ensure it’s used responsibly and not for malicious purposes? The potential for misuse, from generating sophisticated disinformation to automating cyberattacks, is undeniable.
Furthermore, the concentration of power in the hands of a few large tech companies like OpenAI is a growing concern. Transparency, accountability, and broad societal dialogue are essential to navigate these complex ethical challenges.
Benchmarking GPT-4.5 “Orion”: A Mixed Bag of Results
While OpenAI touts GPT-4.5’s advancements, a closer look at its performance on various benchmarks reveals a more nuanced picture. It’s not a clean sweep of victories; instead, the results highlight both strengths and weaknesses, suggesting that the era of simple scaling yielding consistent improvements may be coming to an end.
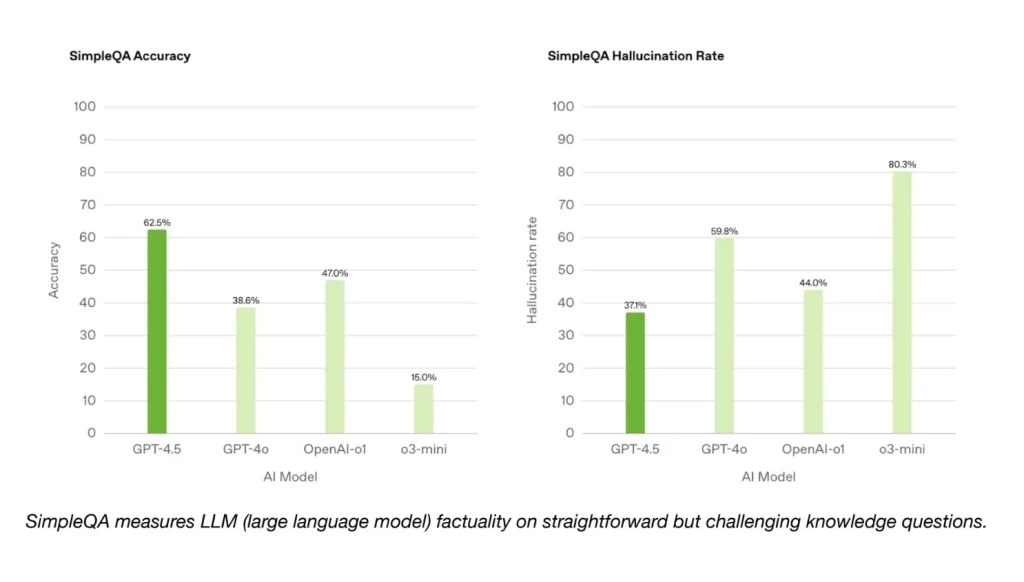
Factual Questioning: A Win on SimpleQA
On OpenAI’s SimpleQA benchmark, designed to test an AI model’s ability to answer straightforward factual questions, GPT-4.5 demonstrates a clear advantage. It outperforms several other models, including previous iterations initially referred to in reporting as models. This aligns with OpenAI’s claim of “deeper world knowledge” and suggests an improved ability to retrieve and present established facts. OpenAI also claims that GPT-4.5 hallucinates less frequently than most models.
However, it’s important to note that OpenAI did not include its top-performing “deep research” model in the SimpleQA comparison. While an OpenAI spokesperson claimed it wasn’t a relevant comparison, Perplexity’s Deep Research model, which performs similarly to OpenAI’s on other benchmarks, was also discussed in the same reporting. This highlights the importance of independent verification and the potential for selective reporting of benchmark results.
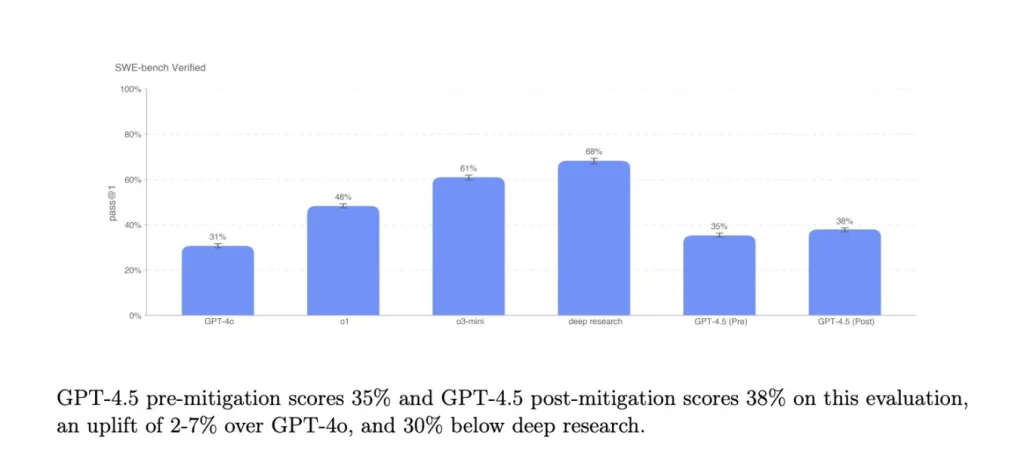
Coding Challenges: Mixed Performance on SWE-Bench and SWE-Lancer
In the realm of coding, GPT-4.5’s performance is more variable. On the SWE-Bench Verified benchmark, which focuses on a subset of coding problems, GPT-4.5 roughly matches the performance of GPT-4o and o3-mini but falls short of other models initially referred to in reporting.
However, on OpenAI’s SWE-Lancer benchmark, which assesses an AI model’s ability to develop complete software features, GPT-4.5 outperforms GPT-4o and o3-mini, but still lags behind the deep research model. This suggests that while GPT-4.5 has improved coding capabilities, it’s not consistently outperforming other models, particularly those specifically designed for complex coding tasks.
Academic Benchmarks: Falling Short on AIME and GPQA
On more demanding academic benchmarks like AIME (American Invitational Mathematics Examination) and GPQA (Graduate-Level Question Answering), which require advanced reasoning and problem-solving skills, GPT-4.5 does not reach the performance of leading AI reasoning models. It falls short of DeepSeek’s models initially referred to in reporting (one of which is technically a hybrid model).
However, GPT-4.5 does match or best leading non-reasoning models on these same tests, indicating a decent level of performance on math- and science-related problems, but not at the cutting edge of reasoning capabilities.
These results strongly suggest that simply increasing the size and computational power of a model, as with GPT-4.5, is not sufficient to achieve breakthrough advancements in complex reasoning. This is where specialized reasoning models, which prioritize efficient and accurate reasoning processes, are beginning to shine.
Beyond Benchmarks: Qualitative Strengths and the Pursuit of “Emotional Intelligence”
While quantitative benchmarks provide valuable data points, OpenAI emphasizes that GPT-4.5 exhibits qualitative improvements that are harder to measure numerically. These include enhanced abilities in understanding human intent, generating more natural and empathetic responses, and performing well on creative tasks.
Understanding Human Intent and Generating Natural Responses
OpenAI claims that GPT-4.5 possesses a “deeper world knowledge” and “higher emotional intelligence,” leading to a greater ability to understand the underlying meaning and purpose behind user prompts. This goes beyond simple keyword recognition and aims to capture the nuances of human communication.
The model is also described as responding in a “warmer and more natural tone,” suggesting improvements in conversational flow and style.
In one informal test, OpenAI prompted GPT-4.5, GPT-4o and o3-mini to create a unicorn in SVG. GPT-4.5 was the only AI model to create anything resembling a unicorn.
Emotional Intelligence and Empathetic Interactions
OpenAI asked GPT-4.5 and the other two models to respond to the prompt, “I’m going through a tough time after failing a test.” GPT-4o and o3-mini gave helpful information, but GPT-4.5’s response was the most socially appropriate.

Creative Tasks and Design Capabilities
OpenAI also highlights GPT-4.5’s performance on creative tasks such as writing and design. While specific examples are provided, these capabilities are inherently more subjective and difficult to evaluate objectively than performance on standardized benchmarks. Nevertheless, they point to a potential broadening of LLM applications beyond purely informational or analytical tasks.
The Scaling Laws Dilemma: Are We Reaching the Limits of “Bigger is Better”?
The release of GPT-4.5 occurs amidst a growing debate within the AI community about the long-term viability of the “scaling laws” approach, which posits that simply increasing the size of a model and its training data will lead to continuous improvements in performance. While this approach has yielded impressive results in the past, there are increasing signs that we may be approaching a point of diminishing returns.
Ilya Sutskever’s “Peak Data” Comments and the Finite Nature of High-Quality Data
OpenAI co-founder and former chief scientist Ilya Sutskever has made comments, discussed in the context of the GPT-4.5 release, suggesting that “we’ve achieved peak data” and that “pre-training as we know it will unquestionably end.”
His comments, and the broader discussion around the limits of scaling, are relevant to the ongoing debate, as acknowledged by TechCrunch. The amount of high-quality text data available for training is finite, and at some point, adding more data will not lead to significant performance gains. This “peak data” scenario forces a reevaluation of how to achieve further advancements in AI.
The Rise of Reasoning Models: A Paradigm Shift?
The performance of GPT-4.5, particularly its limitations on complex reasoning tasks compared to specialized reasoning models, underscores this potential paradigm shift. The industry, including OpenAI, has embraced reasoning models.
By increasing the amount of time and computing power that AI reasoning models use to “think” through problems, AI labs are confident they can significantly improve models’ capabilities. These models prioritize efficient and accurate reasoning processes, often achieving better results on tasks requiring deep understanding and problem-solving, even with smaller model sizes. This suggests that the future of AI may lie not just in building bigger models, but in developing models that are fundamentally better at reasoning and understanding the world.
OpenAI’s Future Plans: GPT-5 and the Integration of Reasoning Capabilities
OpenAI’s future plans, particularly the development of future models, are crucial to observe, as noted in TechCrunch reports. OpenAI plans to eventually combine its GPT series of models with its “o” reasoning series.
GPT-4.5, which was reportedly incredibly expensive to train, delayed several times, and failed to meet internal expectations, may not take the AI benchmark crown on its own. But OpenAI likely sees it as a steppingstone toward something far more powerful.
The company has indicated that it intends to integrate its GPT series of models with its “o” series of reasoning models, potentially combining the strengths of both approaches. This suggests a move towards a hybrid architecture that leverages both the vast knowledge and language generation capabilities of the GPT series and the enhanced reasoning abilities of the “o” series. This could represent a significant step forward, addressing some of the limitations observed in GPT-4.5 and paving the way for more robust and versatile AI systems.
GPT-4.5 – A Stepping Stone, Not a Destination
The OpenAI GPT-4.5 “Orion” release is a complex and multifaceted development in the field of AI. It represents a significant investment in the traditional scaling approach, pushing the boundaries of model size and computational resources. However, its mixed performance on benchmarks, particularly its limitations in complex reasoning compared to specialized models, highlights the potential limits of this approach.
The high cost of access and the ongoing ethical concerns surrounding frontier AI models further complicate the picture.
Ultimately, GPT-4.5 appears to be more of a stepping stone than a final destination. It provides valuable insights into the current state of LLM development, the challenges of scaling, and the growing importance of reasoning capabilities. The future of AI likely lies in a combination of approaches: leveraging the strengths of large language models while also incorporating more sophisticated reasoning techniques and addressing the ethical and societal implications of increasingly powerful AI systems. The journey continues, and GPT-4.5 is a significant, albeit complex, chapter in that ongoing story.
Read More From AI Buzz

Vector DB Market Shifts: Qdrant, Chroma Challenge Milvus
The vector database market is splitting in two. On one side: enterprise-grade distributed systems built for billion-vector scale. On the other: developer-first tools designed so that spinning up semantic search is as easy as pip install. This month’s data makes clear which side developers are choosing — and the answer should concern anyone who bet […]

Anyscale Ray Adoption Trends Point to a New AI Standard
Ray just hit 49.1 million PyPI downloads in a single month — and it’s growing at 25.6% month-over-month. That’s not the headline. The headline is what that growth rate looks like next to the competition. According to data tracked on the AI-Buzz dashboard , Ray’s adoption velocity is more than double that of Weaviate (+11.4%) […]
