
Enfabrica's CXL Fabric Breaks AI Memory Wall via 800GbE

In a significant move targeting the core infrastructure of large-scale AI, semiconductor startup Enfabrica has announced the launch of its Accelerated Compute Fabric Switch (ACFS). This is the industry’s first single-chip solution designed to create a high-performance memory fabric using standard 800GbE Ethernet and the open Compute Express Link (CXL) protocol. The Enfabrica CXL over Ethernet launch directly addresses the critical ‘memory wall’ bottleneck, where the performance of powerful GPUs is constrained by their limited onboard memory. By enabling the disaggregation of memory from compute, the ACFS represents a notable AI memory wall CXL fabric solution for building more efficient and cost-effective AI systems, directly challenging the dominance of proprietary interconnects from market leader NVIDIA. This latest memory disaggregation news signals a strong push towards a more open, composable data center architecture.
Key Points
• Enfabrica’s ACFS launch introduces a single-chip 800GbE switch with native CXL memory fabric capabilities, unifying networking and memory expansion.
• The solution enables memory disaggregation, allowing GPUs to access shared DDR5 memory pools and providing up to 8x memory capacity expansion per accelerator.
• Built on open standards, the fabric presents a direct alternative to NVIDIA’s proprietary NVLink and InfiniBand, with Enfabrica claiming a 50% TCO reduction for LLM inference.
Silicon Symphony: One Chip Orchestrates the Rack
Modern AI models, especially LLMs, are bottlenecked by the “memory wall”—the physical limit of high-bandwidth memory (HBM) that can be attached directly to a single GPU. This forces organizations to use numerous expensive GPUs just to fit a model into memory, leading to inefficient resource use. Enfabrica’s ACFS addresses this by creating a unified, memory-centric fabric on a standard 800-gigabit Ethernet foundation, a move that aligns with market trends showing the rapid adoption of 400GbE and the beginning of the 800GbE ramp.
The ACFS chip integrates networking and memory functions that traditionally require multiple components. As Patrick Kennedy of ServeTheHome notes, “Instead of having to have a NIC, a DPU, a PCIe switch, and a CXL memory controller, Enfabrica is putting a lot of that functionality into its ACF.” It functions as a standard top-of-rack switch for data center traffic while also natively supporting Remote Direct Memory Access (RDMA) for low-latency communication. Its most critical function is integrating Compute Express Link (CXL) memory semantics. This allows banks of less expensive DDR5 RAM to be pooled and shared across thousands of GPUs on the fabric, effectively creating a massive, accessible tier of memory. A GPU first uses its local HBM and then seamlessly accesses this vast CXL memory pool, enabling it to run models far larger than its onboard capacity allows.
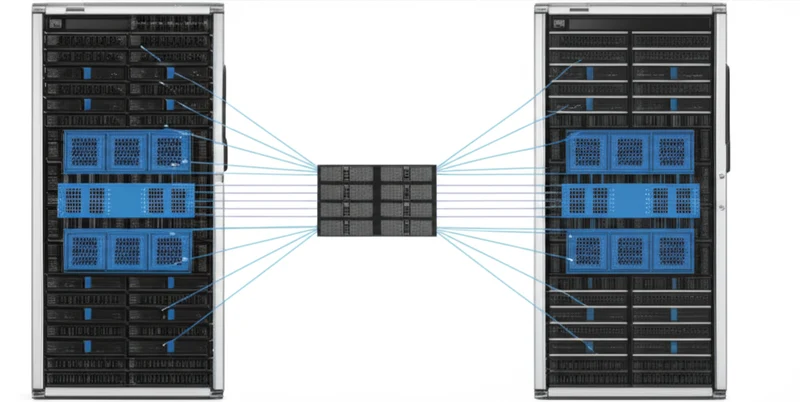
Breaking the Walled Garden: Open Standards Strike Back
Enfabrica’s market entry is a strategic challenge to the established interconnect hierarchy. The AI networking space is currently dominated by NVIDIA’s NVLink, the highest-performance but proprietary solution for tightly-coupled GPUs, and InfiniBand, a high-performance fabric also led by NVIDIA that requires specialized infrastructure. This is a massive market to challenge, with the global data center accelerator space projected to grow to over $245 billion by 2032, driven almost entirely by AI.
By contrast, Enfabrica builds on open standards. Its use of Ethernet leverages a ubiquitous, cost-effective, and multi-vendor ecosystem, while its implementation of CXL aligns with a broad industry movement toward open, coherent memory sharing. The CXL 3.0 specification, released in 2022, introduced the fabric and memory pooling capabilities that Enfabrica’s ACFS now brings to market. This open approach attracts partners like AMD and Intel, who seek to build competitive ecosystems. It also aligns with other CXL pioneers like Astera Labs, whose successful IPO in early 2024 demonstrates strong investor confidence in the CXL market.
Dollars and Data: Decoding the Economics
The central pillar of Enfabrica’s value proposition is a dramatic improvement in economics, highlighted by a claimed 50% Total Cost of Ownership (TCO) reduction for LLM inference. This Enfabrica AI TCO reduction is based on enabling the use of fewer, or less expensive, GPUs by breaking the dependency between compute power and memory capacity. For example, a model requiring eight high-end GPUs for memory might run on a single GPU connected to the Enfabrica fabric.

However, realizing these benefits involves navigating technical trade-offs and hurdles. The ACFS fabric will have higher latency than NVIDIA’s on-package NVLink. The critical question for adopters is whether this latency is low enough for their specific AI workloads. Furthermore, hardware is only part of the equation. A mature and robust software stack is essential to manage the pooled memory and integrate seamlessly with AI frameworks like PyTorch. Competing with NVIDIA’s deeply entrenched CUDA platform is an immense challenge. Still, some analysts see this as a pivotal moment. Dylan Patel of SemiAnalysis states, “Enfabrica is the most promising startup we have seen in years for breaking Nvidia’s monopoly on AI datacenters.” The company’s recently announced $125 million in funding provides the necessary capital to pursue its vision and win over hyperscale customers.
Memory Unleashed: Reimagining AI Infrastructure
Enfabrica’s ACFS is more than just a new switch; it is a tangible implementation of the disaggregated data center vision, a trend highlighted by major industry observers. Gartner, for instance, has identified composable disaggregated infrastructure as a key emerging technology with the potential to significantly improve resource utilization and agility. By separating memory from compute and allowing them to scale independently over an open, standards-based fabric, it offers a new blueprint for building AI infrastructure. This development shifts the focus from simply adding more GPUs to intelligently composing resources for optimal efficiency and cost. The hardware for this new architecture is now entering the market. The pressing question is, will the software ecosystem and market inertia adapt quickly enough to build upon this new foundation?
Tags
Read More From AI Buzz

Perplexity pplx-embed: SOTA Open-Source Models for RAG
Perplexity AI has released pplx-embed, a new suite of state-of-the-art multilingual embedding models, making a significant contribution to the open-source community and revealing a key aspect of its corporate strategy. This Perplexity pplx-embed open source release, built on the Qwen3 architecture and distributed under a permissive MIT License, provides developers with a powerful new tool […]

New AI Agent Benchmark: LangGraph vs CrewAI for Production
A comprehensive new benchmark analysis of leading AI agent frameworks has crystallized a fundamental challenge for developers: choosing between the rapid development speed ideal for prototyping and the high-consistency output required for production. The data-driven study by Lukasz Grochal evaluates prominent tools like LangGraph, CrewAI, and Microsoft’s new Agent Framework, revealing stark tradeoffs in performance, […]
