
MoBluRF NeRF Creates Sharp 4D from Blurry Handheld Video

Researchers from Chung-Ang University (CAU) and the Korea Advanced Institute of Science and Technology (KAIST) have developed a novel framework named MoBluRF, designed to reconstruct sharp, dynamic 4D scenes from blurry, handheld monocular videos. This development, detailed in the journal IEEE Transactions on Pattern Analysis and Machine Intelligence, directly addresses one of the most significant limitations of Neural Radiance Fields (NeRF) technology: its sensitivity to motion blur. By successfully creating crisp 3D models from the shaky, imperfect footage typical of smartphones, MoBluRF represents a notable advancement in making high-fidelity 3D content creation accessible. This new AI turns blurry video into a 4D scene by intelligently separating camera movement from object motion, a breakthrough that lowers the technical barrier for applications in consumer media, robotics, and augmented reality, a significant advancement for the field.
Key Points
- Researchers have introduced MoBluRF, a framework that reconstructs sharp 4D scenes from blurry, single-camera videos.
- The system implements a novel motion decomposition architecture that separates camera shake from object motion for effective deblurring.
- MoBluRF operates without requiring manual motion masks, automating a labor-intensive step common in previous methods.
- This development enables consumer devices like smartphones to generate high-quality, immersive 3D content from casual recordings.
Untangling the Blur: Motion’s Dual Identity
The core innovation of MoBluRF lies in its two-stage architecture designed to resolve the ambiguity that motion blur introduces into NeRF reconstructions. Standard NeRF models, which are trained to map 3D coordinates and viewing directions to color and density, fail when fed blurry images because the smeared visual data makes it difficult to learn precise geometry and camera positions. The MoBluRF NeRF for blurry video tackles this head-on.
The first stage, Base Ray Initialization (BRI), establishes a stable geometric foundation. Instead of trying to deblur from the outset, it first creates a rough 3D reconstruction of the dynamic scene from the blurry video. This initial pass allows the framework to refine the camera’s estimated viewing angles, providing a more accurate starting point for the deblurring process. This initial reconstruction is crucial, as previous methods often failed due to inaccurate camera pose estimations from blurry frames.
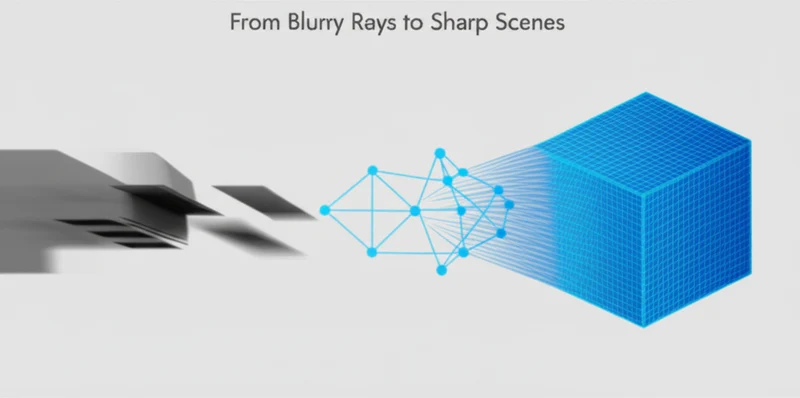
The second stage, Motion Decomposition-based Deblurring (MDD), performs the intricate work of sharpening the scene. It employs a method called Incremental Latent Sharp-rays Prediction (ILSP), which is central to the NeRF motion decomposition architecture. This technique separates the blur into its two main components: global camera motion and local object motion. By incrementally accounting for these distinct movements, the system accurately predicts the sharp light rays that would have been captured in a perfectly stable shot.
Two novel loss functions further enhance this process by automatically separating static and dynamic regions and improving the geometric accuracy of moving objects.
Breaking the Single-Camera Barrier
MoBluRF establishes a new performance benchmark by solving several concurrent challenges that have limited previous 4D reconstruction methods. Its ability to operate effectively on monocular videos—footage from a single camera—is a significant step toward democratizing the technology, removing the need for complex and expensive multi-camera rigs.
A key differentiator is its automated, mask-free workflow. Many existing dynamic NeRF solutions require manual supervision, where users must painstakingly create masks to tell the model which parts of the scene are moving. MoBluRF’s integrated loss function handles this separation automatically, drastically reducing the labor and technical expertise required to prepare data for training. This automation is a critical step in moving from lab-based experiments to practical, real-world tools.

The research demonstrates that MoBluRF outperforms state-of-the-art methods with significant margins, showing robust performance across various degrees of motion blur. This validated superiority solidifies its position as a leading NeRF motion blur solution for real-world video captures.
From Shaky Footage to Digital Twins
By bridging the gap between pristine lab conditions and messy real-world video, MoBluRF’s capabilities have direct implications for several industries. The framework, developed by a joint team from Chung-Ang University (CAU) and the Korea Advanced Institute of Science and Technology (KAIST), is positioned to impact how 3D content is created and used. Its publication in IEEE Transactions on Pattern Analysis and Machine Intelligence confirms its technical credibility.
As Assistant Professor Jihyong Oh explained, the framework enables “smartphones and other consumer devices to produce sharper and more immersive content”. This opens the door for users to generate shareable 3D models or dynamic “3D photos” from a short video clip. For robotics and autonomous systems, the technology helps build more accurate 3D environmental maps in real-time, even during rapid movement. In the VR/AR space, MoBluRF streamlines the asset pipeline, allowing developers to create digital twins of real-world objects and scenes quickly and affordably, accelerating one of the latest handheld video NeRF advances.
When Algorithms Outpace Hardware Limitations
MoBluRF is a foundational development that makes high-quality 4D scene reconstruction significantly more practical. By transforming blurry, everyday videos into sharp, navigable 3D experiences, this two-stage framework removes a major obstacle that has confined many NeRF applications to controlled environments. Its innovative approach to motion decomposition and automated workflow paves the way for a new generation of tools in immersive media, robotics, and digital content creation, confirming its relevance beyond niche academic circles . The next logical step involves optimizing its computational demands for on-device processing.
With the barrier to entry now substantially lower, what new forms of immersive content will emerge from everyday video captures ?
Read More From AI Buzz

Perplexity pplx-embed: SOTA Open-Source Models for RAG
Perplexity AI has released pplx-embed, a new suite of state-of-the-art multilingual embedding models, making a significant contribution to the open-source community and revealing a key aspect of its corporate strategy. This Perplexity pplx-embed open source release, built on the Qwen3 architecture and distributed under a permissive MIT License, provides developers with a powerful new tool […]

New AI Agent Benchmark: LangGraph vs CrewAI for Production
A comprehensive new benchmark analysis of leading AI agent frameworks has crystallized a fundamental challenge for developers: choosing between the rapid development speed ideal for prototyping and the high-consistency output required for production. The data-driven study by Lukasz Grochal evaluates prominent tools like LangGraph, CrewAI, and Microsoft’s new Agent Framework, revealing stark tradeoffs in performance, […]
